
科学网—AI Open|清华大学刘知远、孙茂松团队:知识密集型智能体
 精选
精选
已有 469 次阅读
2026-4-7 10:43
| 系统分类: 科研笔记
近日,东北大学(沈阳)Zhenghao Liu、Yu Gu、Ge Yu与清华大学(北京)Yukun Yan、Zhiyuan Liu、Maosong Sun(通讯作者)等研究者合作,在AI Open上发表了题为“Knowledge Intensive Agents”的综述论文。该工作从智能体(Agent)视角重新审视了检索增强生成(RAG)范式,提出将RAG解释为多个具有不同且互补角色的智能体之间的协作知识过程。论文将知识密集型智能体分为两类角色:知识获取(如路由、查询重写)和知识利用(如知识精炼、响应生成)。在此基础上,论文系统回顾了从朴素RAG到以检索为中心的RAG、以LLM为中心的RAG、再到Agentic RAG的演进路径,并提出了多智能体联合优化框架、基于LLM的数据合成流水线以及基于LLM的自动化评估方法,为下一代知识密集型应用提供了全面的技术路线图。
研究背景
大语言模型(LLMs)在推理和语言理解方面展现出强大能力,但其依赖参数化记忆存储知识的方式导致了幻觉生成、知识更新困难以及隐私泄露等问题,严重影响了其在真实场景中的可靠性。检索增强生成(RAG)通过引入检索模块补充外部知识,有效弥合了参数化记忆与显式检索之间的差距。然而,现有研究大多侧重于优化单一组件(检索或生成),忽视了将LLM视为自主智能体的角度——即能够主动获取知识并策略性地利用知识的智能体(Agent)视角。如何以多智能体协作的视角重新审视和优化RAG整个流程,是当前RAG研究的核心挑战。 研究亮点
1. 从智能体视角重新诠释RAG范式,将知识密集型智能体分为知识获取(路由、查询重写、自适应检索)和知识利用(知识精炼、知识组织与保留、响应生成)两大类角色,提供了统一的分析框架。2. 系统梳理了RAG范式的演进路径:从Naive RAG到Retrieval-Centric RAG、LLM-Centric RAG、再到Agentic RAG(单智能体和多智能体),并通过大量文献调研揭示了各范式的技术特点和局限性。3. 提出多智能体联合优化框架,包括共享奖励优化(Shared Reward Optimization)和差异化数据奖励优化(Differential Data Reward Optimization),将RAG建模为多智能体协作的序贯决策过程,实现端到端的系统优化。4. 提出基于LLM的数据合成流水线和自动化评估方法,通过LLM驱动的域适应数据合成、挑战性任务构造、以及自动评估维度选择(ConsJudge)等方法,为RAG系统的训练和评估提供了完整的技术支撑。 图文导读
图1展示了一个由不同知识密集型智能体组成的RAG系统示例。以“Who are the artists in the traveling wilburys?”为查询,知识获取部分的Query Asking Agent和Routing Agent分别负责生成子查询和路由至合适的多模态数据库,检索到相关文档后,知识利用部分的Refinement Agent对检索内容进行精炼,最终由Generation Agent结合内部参数化记忆生成答案。整个流程展示了知识在多个智能体之间的传递、转化和对齐过程。
 图1:由不同知识密集型智能体组成的RAG系统示例。上半部分为知识获取流程,下半部分为知识利用流程。 表1对不同RAG范式进行了系统比较,涵盖了从Naive RAG到Agentic RAG的完整演进路径。Naive RAG以REALM、RAG、FiD为代表,采用简单的检索-生成流程;Retrieval-Centric RAG引入了检索前(查询重写、子查询生成)和检索后(重排序、过滤)优化;LLM-Centric RAG让LLM内化检索能力并优化检索选择;Agentic RAG则分为单智能体和多智能体两种模式,实现了智能体的自主决策和协作。
图1:由不同知识密集型智能体组成的RAG系统示例。上半部分为知识获取流程,下半部分为知识利用流程。 表1对不同RAG范式进行了系统比较,涵盖了从Naive RAG到Agentic RAG的完整演进路径。Naive RAG以REALM、RAG、FiD为代表,采用简单的检索-生成流程;Retrieval-Centric RAG引入了检索前(查询重写、子查询生成)和检索后(重排序、过滤)优化;LLM-Centric RAG让LLM内化检索能力并优化检索选择;Agentic RAG则分为单智能体和多智能体两种模式,实现了智能体的自主决策和协作。
 表1:不同RAG范式的方法分类与代表性工作比较。 图2详细展示了单个智能体在知识获取和利用中的典型角色。知识获取方面包含四个关键决策:是否检索(Whether to Retrieve,包含知识充分性分析和成本效益分析)、检索什么(What to Retrieve,包括查询重写和子查询生成)、何时检索(When to Retrieve,静态检索与自适应检索)、从哪里检索(Where to Retrieve,扩展和路由知识源)。知识利用方面包括知识精炼(重排序、摘要等)和知识组织与保留(知识表示、知识保留机制)。
表1:不同RAG范式的方法分类与代表性工作比较。 图2详细展示了单个智能体在知识获取和利用中的典型角色。知识获取方面包含四个关键决策:是否检索(Whether to Retrieve,包含知识充分性分析和成本效益分析)、检索什么(What to Retrieve,包括查询重写和子查询生成)、何时检索(When to Retrieve,静态检索与自适应检索)、从哪里检索(Where to Retrieve,扩展和路由知识源)。知识利用方面包括知识精炼(重排序、摘要等)和知识组织与保留(知识表示、知识保留机制)。
 图2:单个智能体在知识获取与利用中的典型角色分工。 图3展示了三种不同类型的多智能体RAG系统架构。第一种是知识获取驱动型(Knowledge-Acquisition-Driven),重点在于通过查询重写和自适应检索来获取更高质量的知识;第二种是知识利用驱动型(Knowledge-Utilization-Driven),侧重于通过精炼智能体去噪和精炼检索内容,并协调参数化知识与外部知识的冲突;第三种是混合型(Hybrid),整合知识获取与利用智能体,实现更全面的协作推理。每种架构都以一个具体的问答示例展示了其工作流程。
图2:单个智能体在知识获取与利用中的典型角色分工。 图3展示了三种不同类型的多智能体RAG系统架构。第一种是知识获取驱动型(Knowledge-Acquisition-Driven),重点在于通过查询重写和自适应检索来获取更高质量的知识;第二种是知识利用驱动型(Knowledge-Utilization-Driven),侧重于通过精炼智能体去噪和精炼检索内容,并协调参数化知识与外部知识的冲突;第三种是混合型(Hybrid),整合知识获取与利用智能体,实现更全面的协作推理。每种架构都以一个具体的问答示例展示了其工作流程。
 图3:三种多智能体RAG系统架构:知识获取驱动型、知识利用驱动型、混合型。 图4展示了多智能体系统优化的两种方法。上半部分为共享奖励优化(Shared Reward Optimization),它将RAG系统建模为一系列智能体的流水线,每个智能体接收前一级的输出并将结果传递给下一级,最终输出用于计算全局奖励信号同时优化所有智能体。下半部分为差异化数据奖励优化(Differential Data Reward Optimization),采用Rollout策略为每个智能体生成多个候选输出,由LLM作为裁判比较优劣,从而为每个智能体提供更精细的优化信号。
图3:三种多智能体RAG系统架构:知识获取驱动型、知识利用驱动型、混合型。 图4展示了多智能体系统优化的两种方法。上半部分为共享奖励优化(Shared Reward Optimization),它将RAG系统建模为一系列智能体的流水线,每个智能体接收前一级的输出并将结果传递给下一级,最终输出用于计算全局奖励信号同时优化所有智能体。下半部分为差异化数据奖励优化(Differential Data Reward Optimization),采用Rollout策略为每个智能体生成多个候选输出,由LLM作为裁判比较优劣,从而为每个智能体提供更精细的优化信号。
 图4:多智能体系统优化示意图。上为共享奖励优化,下为差异化数据奖励优化。 表2全面列出了知识密集型任务的代表性数据集,涵盖开放域问答(Natural Questions、TriviaQA、MS MARCO等)、阅读理解(SQuAD、NarrativeQA等)、推理(GSM8K、MATH、StrategyQA等)、多跳问答(HotpotQA、MuSiQue等)、事实核查(FEVER)、摘要(CNN/DailyMail)等多种任务类型,为RAG研究提供了全景式的基准参考。
图4:多智能体系统优化示意图。上为共享奖励优化,下为差异化数据奖励优化。 表2全面列出了知识密集型任务的代表性数据集,涵盖开放域问答(Natural Questions、TriviaQA、MS MARCO等)、阅读理解(SQuAD、NarrativeQA等)、推理(GSM8K、MATH、StrategyQA等)、多跳问答(HotpotQA、MuSiQue等)、事实核查(FEVER)、摘要(CNN/DailyMail)等多种任务类型,为RAG研究提供了全景式的基准参考。
表2:知识密集型任务的代表性数据集概览。 图5展示了基于LLM的域适应数据合成架构。该流水线包含三个步骤:Schema Extraction(从Seed文档提取结构化模式)、Configuration and Document Synthesis(基于Schema生成配置和文档)、Question-Answer Generation(生成问答对并通过LLM Reference进行精炼)。该方法能够自动合成高质量的域特定数据,用于训练和评估RAG系统。 图5:基于LLM的域适应数据合成架构,包含Schema提取、配置合成和问答生成三个阶段。 图6展示了针对挑战性RAG任务的数据合成架构。该方法利用知识图谱和LLM自动生成复杂的多跳推理数据,包括多跳路径构建(Multi-hop Path Construction)、属性模糊化(Blurring Attributes)以增加难度、以及合成挑战性问答对(Synthesize Challenging QA Pair)等步骤,以克服现有基准测试集过于简单的问题。
图5:基于LLM的域适应数据合成架构,包含Schema提取、配置合成和问答生成三个阶段。 图6展示了针对挑战性RAG任务的数据合成架构。该方法利用知识图谱和LLM自动生成复杂的多跳推理数据,包括多跳路径构建(Multi-hop Path Construction)、属性模糊化(Blurring Attributes)以增加难度、以及合成挑战性问答对(Synthesize Challenging QA Pair)等步骤,以克服现有基准测试集过于简单的问题。 图6:基于知识图谱和LLM的挑战性RAG数据合成架构。 图7展示了使用原始指标评估RAG系统时面临的挑战。上半部分展示了过度估计(Overestimation)的例子:当模型响应在表面上与参考答案匹配但实际不正确时,自动指标会错误地给出高分。下半部分展示了低估(Underestimation)的例子:当模型给出语义等价但表面形式不同的正确答案时,基于字符串匹配的指标会错误地判为不正确。
图6:基于知识图谱和LLM的挑战性RAG数据合成架构。 图7展示了使用原始指标评估RAG系统时面临的挑战。上半部分展示了过度估计(Overestimation)的例子:当模型响应在表面上与参考答案匹配但实际不正确时,自动指标会错误地给出高分。下半部分展示了低估(Underestimation)的例子:当模型给出语义等价但表面形式不同的正确答案时,基于字符串匹配的指标会错误地判为不正确。

图7:使用原始指标评估RAG时的过度估计和低估问题示例。 图8展示了基于LLM的评估方法中存在的一致性问题。当使用不同的评估维度(幻觉、完整性、连贯性、语义一致性)提示LLM裁判选择最佳响应时,不同维度可能导致不同的排名结果,揭示了当前LLM评估方法对提示设计和评估维度选择的敏感性。 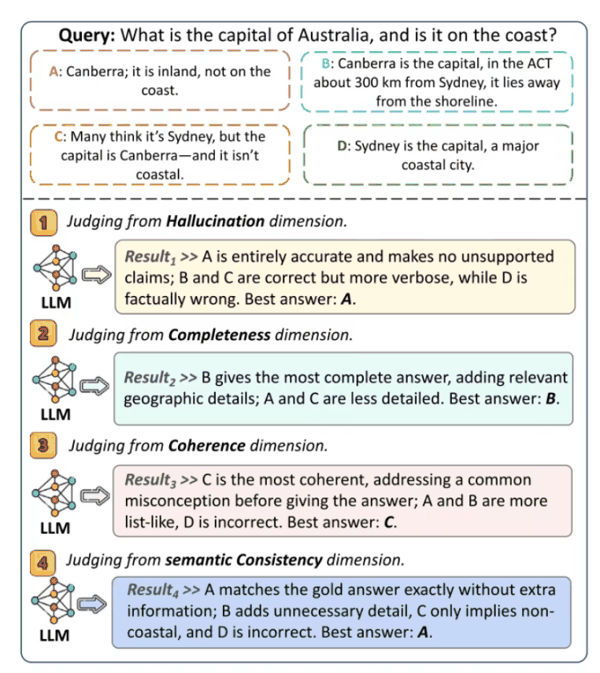
图8:基于LLM的评估中不同评估维度导致的不一致性示例。 图9展示了自动评估维度选择架构(ConsJudge)。该方法先从Dimensions Pool中选择合适的评估维度组合,然后根据所选维度构建Prompt提示LLM进行评分,并通过奖励信号训练LLM自适应地选择最优的评估维度组合。这一方法超越了人工设计提示词的局限,使评估模型能够更好地泛化到不同任务和领域。 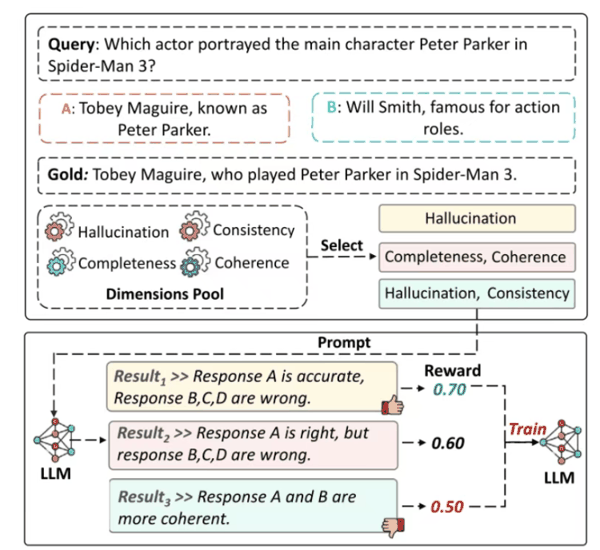
图9:ConsJudge自动评估维度选择架构,通过奖励信号优化评估维度组合。 原文信息
Knowledge Intensive AgentsZhenghao Liu, Pengcheng Huang, Zhipeng Xu, Xinze Li, Shuliang Liu, Chunyi Peng, Haidong Xin, Yukun Yan, Shuo Wang, Xu Han, Zhiyuan Liu, Maosong Sun, Yu Gu, Ge YuAI Open, Volume 7, Pages 18–44, 2026DOI: https://doi.org/10.1016/j.aiopen.2026.02.002 期刊介绍
 AI Open是一本致力于分享人工智能及其应用理论的英文国际期刊,期刊侧重人工智能领域可操作知识层面及具有前瞻性观点的研究。期刊主编由清华大学计算机与科学技术系唐杰教授担任。
AI Open是一本致力于分享人工智能及其应用理论的英文国际期刊,期刊侧重人工智能领域可操作知识层面及具有前瞻性观点的研究。期刊主编由清华大学计算机与科学技术系唐杰教授担任。
AI Open欢迎人工智能及其应用相关领域的文章。
期刊收录的所有文章都经过严格的同行评审,并发表在月活用户超过2000万的ScienceDirect平台,供领域内的学者、及全球读者免费阅读、下载及引用。
目前,期刊已被ESCI、Ei Compendex、Scopus、DOAJ、dblp computer science bibliography、EBSCOhost等权威数据库收录。在COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS学科175种国际期刊中位列第3位(Q1区),在COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE学科204种国际期刊中位列第5位(Q1区)。
主编
唐杰,清华大学
Björn W. Schuller, Imperial College London
副主编
Wendy Hall, University of Southampton
Michalis Vazirgiannis,Ecole Polytechnique
Jose A. Lozano,University of the Basque Country UPV/EHU
Esma Aïmeur,University of Montreal, Canada
刘知远,清华大学
张静,中国人民大学
东昱晓,清华大学
吴乐,合肥工业大学
马家祺,University of Illinois Urbana-Champaign, USA
何向南,中国科学技术大学
邱锡鹏,复旦大学
转载本文请联系原作者获取授权,同时请注明本文来自科爱KeAi科学网博客。 链接地址: https://blog.sciencenet.cn/blog-3496796-1529235.html
上一篇: Fundamental Research |董旭等:当飞机的“呼吸”不再顺畅:航空发动机进气-压缩系统的相容性挑战 下一篇: 日本秋田县立大学Kenichi Arai团队:开发一种基于原代肝细胞的临床前球体模型系统,用于分析体外I期和II期酶活性